When building integration solutions, there is often a need for workflow automation and orchestration capabilities. With so many options on the market, most of which are proprietary, I thought I would share with you an open source alternative called Apache NiFi which in my experience has a lot to offer in solving enterprise-level integration challenges.
Although it has a bit of a learning curve there’s a lot of room for Nifi in the enterprise landscape, particularly when it comes to the movement of data. When applied in the right scenarios is it clearly a tool worth considering, with particular strengths in managing Big Data and with the added benefits of open source, reduced cost and being vendor agnostic.
In this article, I will explore Apache NiFi as it relates to enterprise workflow automation, and draw on my experience working with it to discuss some of its powerful features and its limitations when considering whether you should use it to manage your workflow automation & orchestration.
What is Apache NiFi?
Apache NiFi originally began its development by the US National Security Agency as “NiagaraFiles” before becoming part of the Apache Software Foundation. It is essentially promoted as a software tool designed to automate the flow of data between software systems. It is built using the Java Programming language and is designed based on a flow-based programming model. Its main components include a HTTP-based Web Server, which allows you to visually build, control and monitor those workflow processes; a flow controller for managing the execution of flows; and repositories that store flow files, content and provenance data about flow runs.
Having worked on NiFi for the first time, one of the things I instantly noticed was just how similar it was to other workflow tools like Azure LogicApps or even CA Automic. Having been responsible for rolling out a Workflow automation strategy using a commercial based solution, one cannot help to make comparisons and ultimately question whether the extra support you get is worth the cost.
Using the right tool for the job is important – I have seen the wrong thing done by many organisations where they try to fit a round peg in a square hole, like using full enterprise iPaaS platforms for batch processing. Great if you want costs to soar.
Where does NiFi Shine?
Since NiFi’s main purpose is to automate the transfer of data between systems, it works best in Extract, Transform and Load (ETL), workflow automation and orchestration, batch processing and task scheduling type scenarios. Essentially, it is capable of dealing with many situations that involve the movement of data between source and destination where the data that is being funnelled through needs to be transformed and orchestration needs to occur in between.
One of the things that make NiFi so attractive is the support for many types of upstream and downstream systems, especially its support for SaaS and cloud services. Below is a non-exhaustive list of some of the most popular:
- retrieves and moves files from disk or network storage
- supports file transfer protocols like FTP and SFTP
- supports event streaming using Kafka
- supports HDFS (Apache Hadoop)
- connect to AWS services such as S3, SNS, Lambda, SQS and DynamoDB. For instance, creating a schedule that polls an AWS S3 bucket for incoming files
- connect to Azure services such as Blob and Queue Storage, EventHub, CosmosDb
- connect to Google Cloud Services.
- connect to Slack
- support for IMAP, Mail, JMS
- Connections to SQL databases and other data sources including NoSQL databases like Cassandra and MongoDB
- support for ElasticSearch
- Web Services and REST API endpoints
- Script execution
Given the array of solutions it is designed to cater for and the systems it supports, NiFi certainly brings a lot to the table when it comes to handling data in your organisation. So let’s look at some of the features and capabilities provided by NiFi that I found useful.
Best Features Provided by NiFi
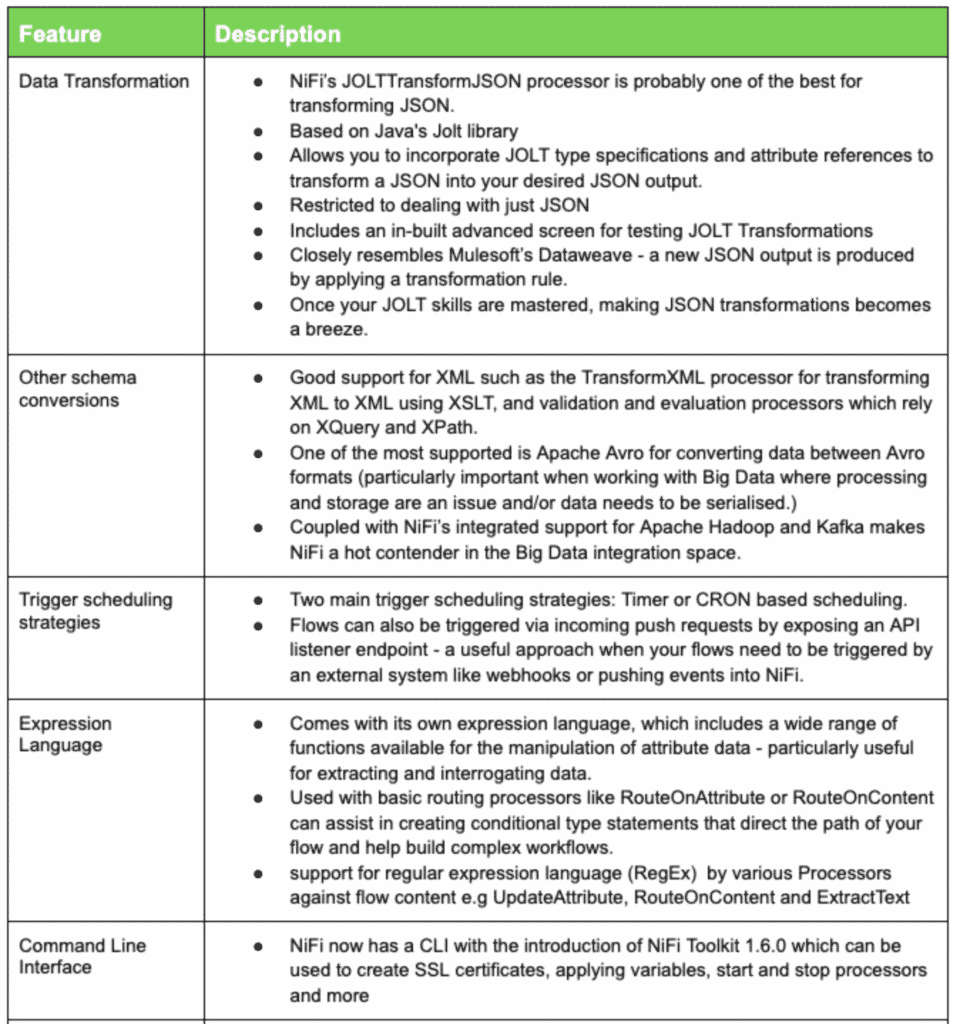
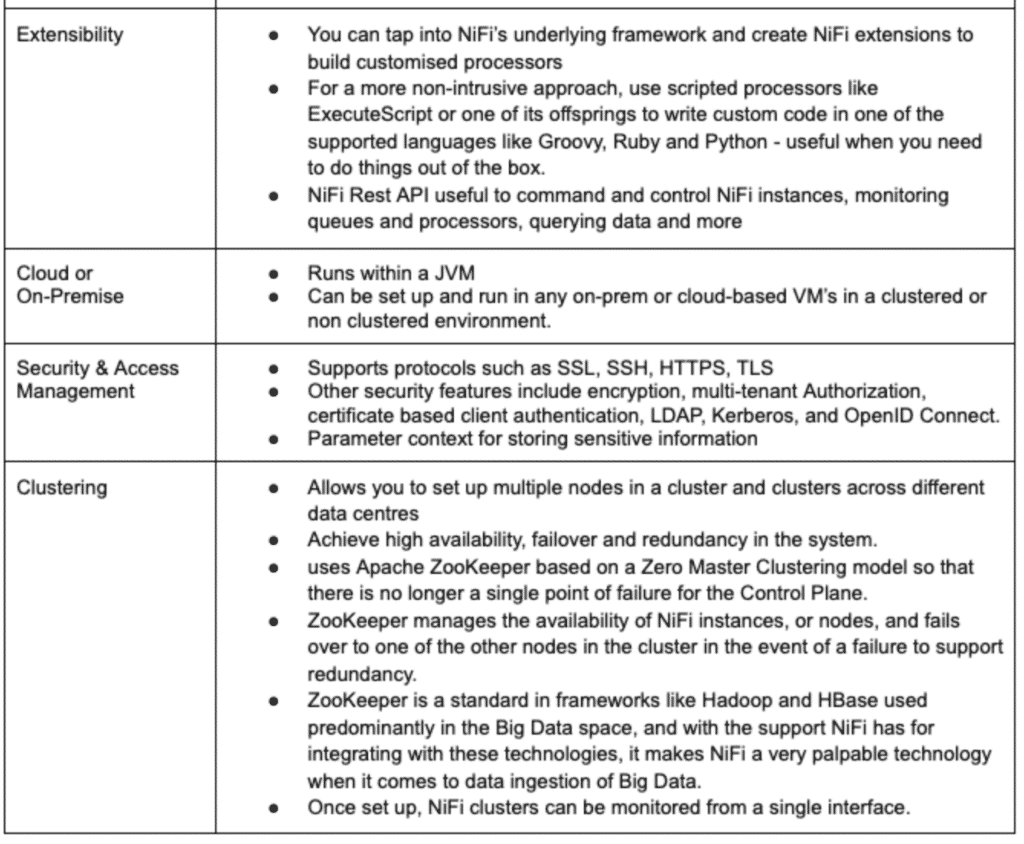
Some Cons but not Show Stoppers
Although Nifi is strong technologically it does have some problems that, while there may be workarounds, will add to the overall cost of the project. Below are some limitations that I found that, while they are not show stoppers, need to be taken into account when deciding to use NiFi.
Error Handling
Error handling in NiFi is done using the Routing Relationships that each processor provides to deal with errors. However, the types of errors they route are not consistent across all the processors. As a result, understanding each of these failure routing relationships or just handling them can be a challenge and a time consuming process, at least until a strong foundation can be incorporated into your flows. You will usually need to handle these errors by sending an email to an Ops team or something more elaborate. This will ultimately require you to build your own logging framework that other flows can also then reuse. For instance, retry policies on API timeout errors may be achieved using a combination of the RetryFlowFile and the retry relationship that would otherwise be much easier in other technologies. So a lot of the time extra effort may be required to meet your specific needs.
Lack of Support for External Code Repositories
Another drawback of NiFi is its lack of support for, or the ease of exporting flow descriptors into external code repositories like GIT. I mentioned reuse above; well, even though NiFi does have its own native repository (NiFi Registry) it does not do a great job when it comes to sharing versioned child processor groups, and although it does a good job when deploying or importing processor groups into different NiFi instances it does not support branching or merging. Therefore, trying to achieve a level of reusability and modularity can often be cumbersome and using NiFi Templates to do this is impractical in large-scale projects. Large-scale projects with multiple development streams and releases will also definitely struggle and as a result would need to be managed carefully by the DevOps team.
Statistical Information About Flows
Statistical information about the flows and processors is a little disjointed. Even though, It has native monitoring through the Bulletin Board and NiFi Reporting Tasks, which you need to create to monitor the NiFi Instances, it generally just lacks cohesion. Nonetheless, it is good to know that you can potentially use the NiFi Rest API and build your own monitoring framework that meets your requirements.
Generally, NiFi only keeps a 5 minute running average on the processors which is not configurable. This is where you need to scour through Data provenance and the information kind of gets cluttered with all the different provenance events. The good thing is data that is kept in Data provenance is configurable and retention times can be adjusted to suit your needs. While each processor has a Status History where you can gather more information about your processors and set retention times, it is generally limited in its capabilities in catering for your needs.
Processor inconsistencies
A final note to consider is the lack of consistency between all its processors especially when it comes to their support for expression use, which they do not all support. Also the many different routing relationships that one must deal with can act as a distraction for newbies, or the various types of provenance events that quickly explode when sifting through log history. Other than that, you will often find yourself in an intimate relationship with each and every processor to some extent, but being aware of these things will help your journey.
Conclusion
There are definitely many gotchas and limitations when using NiFi, it can feel quirky and strange at times but with some patience, it is a tool well worth the hassle that fits well in unlocking some of the analytical data paradigms like Big Data, at a comparatively lower cost.

