Five years ago a data warehouse was a one stop shop for all of your data and analytics needs. The types and sources of data a business has access to has grown exponentially in this time though and businesses need to expand their data strategy beyond the data warehouse if they want to use their data for intelligent decision making, competitive advantage and business growth. In this blog we’re going to discuss the key ingredients you need for a holistic data strategy.
Data Storage, Beyond the Data Warehouse
A data warehouse is a database optimised to analyse relational data from transactional systems and line of business applications. There is a big emphasis on data quality as data can only be entered into the data warehouse via a predetermined structure and schema. However if it’s not in a database, you can’t analyse it.
Data lakes originated to bridge the gap and enable analytics to be derived from a range of different sources including journal entries, objects/documents, unstructured, csv files, IoT & event streams, pictures, videos, GraphQL and log files. It stores the raw source data and provides the ability to discover and explore it so you don’t need to know your analytics requirements upfront and you can use a wider variety of data sources to make business decisions.
Capturing data in a Data Lake significantly reduces analytics turnaround time and helps organisations empower their data users which facilitates better collaboration, faster decision making and the exploration of new use cases such as Machine Learning or Research & Development.
Data Lake Challenges
According to AWS ‘the main challenge with a data lake architecture is that raw data is stored with no oversight of the contents. For a data lake to make data usable, it needs to have defined mechanisms to catalog, and secure data. Without these elements, data cannot be found, or trusted resulting in a “data swamp.” Meeting the needs of wider audiences require data lakes to have governance, semantic consistency, and access controls.’
To get the most out of your data lake we suggest you consider the following:
- Catalogue Data to Keep the Lake from Becoming a Swamp
- Allow for an ecosystem with a wide variety of tools & patterns to feed data into your data lake e.g. Extract Transform Load (ETL), event streaming, Change Data Capture (CDC), file transfers.
- Cloud-Based or Hybrid Architecture?
- Make Your Cloud-Based Data Lake a Nexus for Sharing Modern and Traditional Data
- Use the Data Lake as a fine grained, safe & secure Self-Service Data Exploration Platform
Data Governance
For a business to leverage their data it is essential they know where data is located, how it originated, who has access to it, what it contains, and that it is trustworthy whilst adhering to government compliance and policies. While a data lake addresses the ingestion, storage and access to the finely grained data, data governance focuses on improving the utilization, processing and quality of data. This is achieved by forming a team and developing patterns that are responsible for the data’s accuracy, availability, completeness, consistency, timeliness, validity, compliances, and uniqueness.
The key components of a good approach to data governance include:
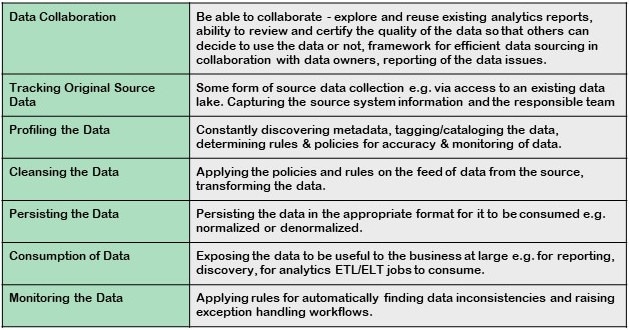
In our experience data profiling is one of the most important steps in data governance. Profiling the data provides a holistic view of the data source which includes the statistics, quality and suitability of the data at an early stage in data intensive projects. It also helps data discoverability by providing the added tags and categories. Data access control can also be achieved by suitably adding confidentiality information in the form of tags or categories on the data as part of data profiling.
Some data profiling steps could include:
- Collecting descriptive statistics like min, max, count and sum.
- Collecting data types, length and recurring patterns.
- Tagging data with keywords, descriptions or categories.
- Performing data quality assessment, risk of performing joins on the data.
- Discovering metadata and assessing its accuracy.
- Identifying distributions, key candidates, foreign-key candidates, functional dependencies, associations and uniqueness, embedded value dependencies and performing inter-table analysis.
A good data profiling initiative also aims to go further than acknowledged industry techniques by understanding the business processes, how functional teams work with the data, understanding the business, their customers, typical problems teams have with the data, etc. With this context many more monitoring rules and transformation policies can be applied to improve quality.
Conclusion
“A digital business cannot exist without data and analytics. If an organization struggles with digital transformation, perhaps they haven’t given enough thought to data and the potential for valuable insights.” Gartner.
With the volume, value, and different types of data continually growing it is clear that having a holistic data strategy is critical for business success in the digital era. The question is how can you best mature your data and analytics capability so you can become a data-driven business sooner rather than later.


